Salut, de retour pour un nouveau tutoriel dev. Cette fois, nous allons dévélopper ensemble une application de bureau avec Electron, React, Ts, Python et du CSS avec Tailwind. Nous allons l’appeler PDF Semantic Search, mais à vous de choisir le meilleur nom pour votre application.
PDF Semantic Search est une application desktop locale conçue pour indexer des documents PDF, retrouver rapidement les bons extraits et répondre à des questions avec des citations claires. Le projet repose sur Electron, React, SQLite, PDF.js, FastAPI et Sentence Transformers. Il s’adresse normalement, et dans version la plus optimale aux entreprises, indépendants, équipes RH, juridiques, administratives ou techniques qui veulent un moteur de recherche documentaire moderne sans envoyer leurs fichiers vers un service cloud. Dans notre cas, on va l’utiliser en local, il faudra par la suite améliorer quelques modules pour une mise en production à grande échelle.
Ce que fait concrètement l’application:
L’application PDF Semantic Search permet notamment :
- d’importer une bibliothèque de PDF
- d’indexer les documents en tâche de fond
- d’extraire le texte page par page
- de lancer un OCR sur les pages difficiles à lire
- de rechercher un terme, une phrase ou une question
- d’obtenir des résultats classés avec citations
- d’ouvrir directement le PDF à la bonne page
- de poser une question à un assistant local
- et d’organiser les documents avec des tags, collections et favoris
Le positionnement du projet est simple : garder les données locales, améliorer la vitesse de recherche et produire des réponses documentaires plus utiles qu’une recherche classique dans un lecteur PDF standard.
Une application comme celle-ci doit répondre à plusieurs contraintes en même temps :
- lire correctement des PDF très différents
- rester rapide quand la bibliothèque grandit
- garder les documents en local
- être simple à déployer pour un usage desktop
- permettre une évolution progressive vers plus d’intelligence
Electron ici apporte le cadre desktop. React gère l’interface. SQLite assure la persistance locale. Python reste le meilleur choix pragmatique pour les embeddings locaux. Le résultat est une architecture robuste, claire et adaptée à une application documentaire moderne.
Technologies utilisées dans ce projet :
Côté desktop et interface
- Electron pour l’application desktop
- React pour l’interface
- TypeScript pour la sûreté du code
- Vite et electron-vite pour le build et le développement
- Tailwind CSS pour le style
Côté données et recherche
- SQLite avec `better-sqlite3`
- SQLite FTS5 pour la recherche par mots-clés
- embeddings locaux pour la recherche sémantique
Côté PDF et OCR
- PDF.js pour la lecture et l’extraction
- react-pdf pour l’affichage dans l’interface
- Tesseract.js pour l’OCR
Côté IA locale
- FastAPI pour le micro-service Python
- Sentence Transformers pour les embeddings
- Ollama en option pour des réponses plus riches
Les Fonctionnalités développées dans l’app:
F1: Import et gestion de bibliothèque
L’utilisateur peut importer des PDF directement ou scanner un dossier complet. Chaque document est enregistré dans une base locale avec ses métadonnées principales : chemin, taille, statut d’indexation, qualité de texte, OCR utilisé, modèle d’embedding utilisé et autres informations utiles.
F2: Indexation en arrière-plan
L’indexation est orchestrée par une file persistante. L’application peut reprendre des tâches après un redémarrage. Cette approche est importante pour un vrai logiciel desktop, car elle évite de perdre le travail déjà commencé.
F3: Extraction de texte
Le moteur lit les pages, reconstruit plus proprement les lignes et paragraphes, puis normalise le texte. L’objectif n’est pas seulement de lire le PDF, mais de créer une base exploitable pour la recherche et les réponses.
F4: OCR ciblé
L’OCR n’est pas limité aux PDF totalement scannés. L’application peut aussi renforcer uniquement les pages pauvres en texte. C’est plus précis, plus rapide et plus réaliste pour des documents mixtes.
F5: Recherche hybride
La recherche combine deux approches :
- le lexical, très fort sur les mots exacts, via FTS5
- le sémantique, très utile pour les formulations proches, via embeddings
Les résultats sont fusionnés puis rerankés pour donner des extraits plus clairs, plus complets et plus proches de l’intention utilisateur.
F6: Assistant documentaire
L’assistant local peut répondre de deux façons :
- par extraction intelligente de phrases pertinentes
- via Ollama, si un modèle local est disponible
Dans les deux cas, le but est de produire des phrases complètes, précises et ancrées dans les sources.
F7: Viewer PDF enrichi
Le viewer permet :
- ouverture du PDF à la bonne page
- zoom
- rotation
- navigation
- plan du document
- surlignage de texte
- copie de citation
- diagnostic des erreurs d’ouverture
Structure du Projet et Rôle de chaque dossier:
L’application suit une architecture desktop classique en trois couches côté Electron: le main process, le preload et le renderer. À cela s’ajoutent une couche partagée pour les contrats, un service Python local pour les embeddings, un système de migrations SQLite et quelques scripts d’outillage. Cette organisation permet de séparer clairement l’interface, la logique métier, l’accès natif au système et les traitements IA locaux.
pdf-semantic-search/
├─ src/
│ ├─ main/
│ ├─ preload/
│ ├─ renderer/
│ └─ shared/
├─ python/
├─ resources/
│ └─ migrations/
├─ scripts/
├─ docs/
├─ package.json
├─ electron.vite.config.ts
└─ README.md
Le dossier src/main
Contient le cœur applicatif Electron : base SQLite, protocole `pdfdoc://`, indexation, recherche, assistant, watchers et logique métier globale.
C’est dans ce dossier que se trouvent les points d’entrée techniques les plus sensibles du projet. On y gère le cycle de vie de l’application, la création de la fenêtre Electron, l’initialisation de la base, l’enregistrement des handlers IPC et l’orchestration des services.
Informations complémentaires utiles :
- index.ts joue le rôle de composition root. Il instancie les services, relie les couches entre elles et déclare le protocole personnalisé utilisé pour charger les PDF.
- db/ contient la gestion de la connexion SQLite et l’exécution des migrations.
- services/ regroupe la logique métier par domaine, ce qui évite d’avoir un main monolithique.
- store.ts centralise la configuration persistante de l’application.
- logger.ts sert à homogénéiser les logs structurés côté process principal.
En pratique, ce dossier ne devrait pas contenir de logique d’interface. Il sert de couche d’orchestration et d’accès aux capacités natives.
Le dossier src/preload
Expose une API sécurisée au renderer. Cette couche est essentielle pour garder une séparation propre entre interface et logique native.
Cette couche sert d’interface contrôlée entre Electron et le front React. Elle expose uniquement les méthodes nécessaires, sans donner un accès direct à Node.js au renderer.
Informations complémentaires utiles :
- le preload agit comme une façade stable pour le front ;
- il limite la surface d’exposition de l’application, ce qui simplifie la sécurité et la maintenance ;
- il permet de typer proprement les appels et de garder une API unique, même si l’implémentation côté main évolue.
C’est aussi le bon endroit pour standardiser les retours, valider certains formats simples et encapsuler les abonnements aux événements.
Le dossier src/renderer
Contient l’interface utilisateur React. On y trouve les vues, composants, modales, listes, panneaux de résultats et le viewer PDF.
Ce dossier contient toute l’expérience utilisateur visible. Il concentre les écrans, composants, comportements UI, états locaux et interactions côté client.
Informations complémentaires utiles :
- src/ui/views regroupe les écrans métier principaux ;
- src/ui/components contient les briques réutilisables ;
- le viewer PDF est une pièce centrale de ce dossier, car il relie les résultats de recherche à la lecture réelle du document ;
- c’est aussi ici que l’on gère les feedbacks visuels, les toasts, les chargements, les erreurs d’ouverture et les interactions clavier.
Cette couche ne doit pas connaître les détails internes de SQLite, des migrations ou du filesystem. Elle consomme uniquement l’API exposée par le preload.
Le dossier src/shared
Regroupe les modèles partagés et les schémas Zod. Cela garantit une communication IPC plus propre et plus fiable.
Ce dossier sert de contrat commun entre les couches. Il évite les divergences entre ce que le main expose et ce que le renderer attend.
Informations complémentaires utiles :
- ipc.ts formalise les canaux IPC, les requêtes et les réponses ;
- models.ts centralise les types métier partagés par plusieurs couches ;
- l’usage de Zod ici permet de garder des schémas lisibles, réutilisables et validables à l’exécution.
C’est une couche très importante pour la robustesse du projet, car elle réduit les erreurs de synchronisation entre backend desktop et interface.
Le dossier python
Contient le micro-service local chargé de produire les embeddings. C’est aussi le bon endroit pour faire évoluer les traitements NLP locaux.
Ce dossier ne sert pas uniquement à “faire tourner un modèle”. Il constitue une brique indépendante, pensée comme un micro-service local spécialisé.
Informations complémentaires utiles :
- server.py expose les endpoints utilisés par l’application Electron ;
- requirements.txt verrouille les dépendances du service ;
- la séparation Node.js / Python permet de garder le meilleur outil pour chaque besoin ;
- cette couche peut évoluer plus tard vers du reranking, du résumé local ou d’autres traitements documentaires.
Le fait d’avoir isolé cette partie dans un dossier dédié simplifie fortement les évolutions IA sans alourdir le code Electron principal.
Le dossier resources/migrations
Contient les migrations SQLite. Elles structurent la base locale et permettent au projet d’évoluer proprement sans casser les données.
Ce dossier représente l’historique de la structure de la base. Il ne sert pas seulement à créer les tables, mais aussi à faire évoluer proprement le modèle de données dans le temps.
Informations complémentaires utiles :
- les migrations sont append-only ;
- chaque fichier correspond à une étape d’évolution identifiable ;
- elles couvrent non seulement les tables métiers, mais aussi les index, caches et ajustements FTS ;
- ce dossier est essentiel pour garantir une montée en version fiable sans réinitialiser les données utilisateur.
C’est aussi un bon indicateur de la maturité du projet, car il montre comment la donnée a été pensée dans la durée.
Le dossier scripts
Regroupe les scripts utilitaires liés au rebuild Electron, au lancement et au diagnostic. Ce dossier sert à automatiser les tâches de maintenance technique autour du projet.
Informations complémentaires utiles :
- certains scripts existent pour résoudre les contraintes propres à Electron et aux modules natifs ;
- ils évitent de répéter manuellement des commandes fragiles ;
- ils facilitent le diagnostic local, notamment quand un binaire natif ou une indexation pose problème ;
- ils servent aussi de point d’entrée technique pour industrialiser le projet plus tard.
C’est le bon endroit pour mettre tout ce qui relève du support au développement, mais pas du produit lui-même.
Développement de l’application :
Le développement de PDF Semantic Search repose sur deux environnements complémentaires : Node.js pour l’application desktop Electron et Python pour le service local d’embeddings. Cette séparation permet de garder une interface moderne côté desktop tout en profitant de l’écosystème Python pour les traitements sémantiques et NLP.
L’installation se fait donc en deux temps :
- l’environnement JavaScript pour l’interface, le process principal Electron, le preload et toute la logique desktop ;
- l’environnement Python pour le moteur d’embeddings local utilisé par la recherche sémantique.
Cette organisation est volontairement pragmatique. Elle permet d’isoler les dépendances lourdes liées à l’IA locale, de mieux diagnostiquer les problèmes et de faire évoluer chaque couche indépendamment.
Prérequis
- Node.js 20+
- Python 3.10+
En complément des versions minimales, il est utile de préciser que :
- Node.js est utilisé pour lancer le mode développement, compiler le projet, reconstruire les dépendances natives Electron et produire les builds finaux ;
- Python sert uniquement au micro-service local, ce qui veut dire que l’application peut continuer à fonctionner en mode partiel même si la couche sémantique est indisponible ;
- sur Windows, PowerShell est l’environnement le plus cohérent pour suivre les commandes telles qu’elles sont écrites dans le projet.
Pour un développement fluide, il est aussi recommandé de :
- travailler avec une version récente et stable de Node 20 ;
- garder un environnement virtuel Python dédié au projet ;
- éviter de mélanger plusieurs installations Python non maîtrisées sur la même machine.
Installation
npm install
cd python
python -m venv .venv
.\.venv\Scripts\Activate.ps1
pip install -r requirements.txt
cd ..
L’installation prépare en réalité trois choses :
- les dépendances front et desktop ;
- le service Python ;
- la compatibilité des modules natifs Electron, notamment SQLite.
Le dossier python/.venv permet d’isoler le service embeddings du reste de la machine. C’est important pour garder un environnement reproductible, surtout si le projet doit être repris plus tard ou publié publiquement.
Lors du premier démarrage réel, certaines ressources peuvent aussi être téléchargées automatiquement, notamment le modèle d’embeddings si aucun chemin local n’a été configuré. Ce comportement doit être anticipé si l’objectif est un mode strictement offline.
Lancement
npm run dev
La commande de développement ne fait pas qu’ouvrir une fenêtre Electron. Elle enchaîne plusieurs étapes :
- rebuild des dépendances natives pour la version Electron utilisée ;
- build du process principal ;
- build du preload ;
- démarrage du serveur de développement renderer ;
- lancement de l’application Electron ;
- initialisation éventuelle du service Python au premier besoin.
Autrement dit, npm run dev orchestre tout le cycle de développement local. C’est la bonne commande pour travailler sur l’application complète, pas seulement sur l’interface.
Vérifications
npm run typecheck
npm run test
npm run lint
Présentation des interfaces graphiques
L’interface de PDF Semantic Search a été pensée pour rester simple à utiliser, tout en couvrant l’ensemble du cycle documentaire : import, indexation, recherche, lecture, organisation et configuration. L’application est structurée autour de plusieurs vues principales, chacune ayant un rôle précis dans l’expérience utilisateur.
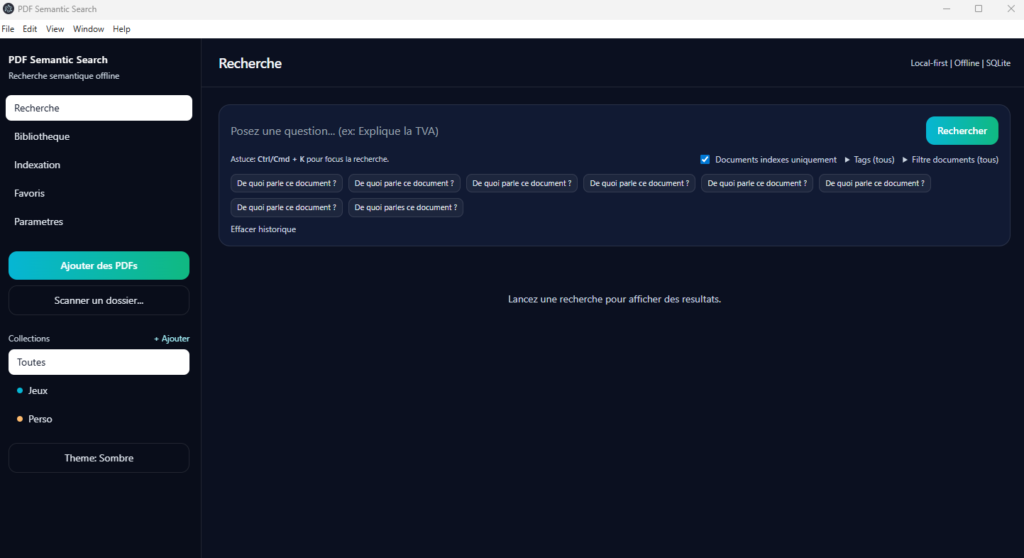
1. La bibliothèque
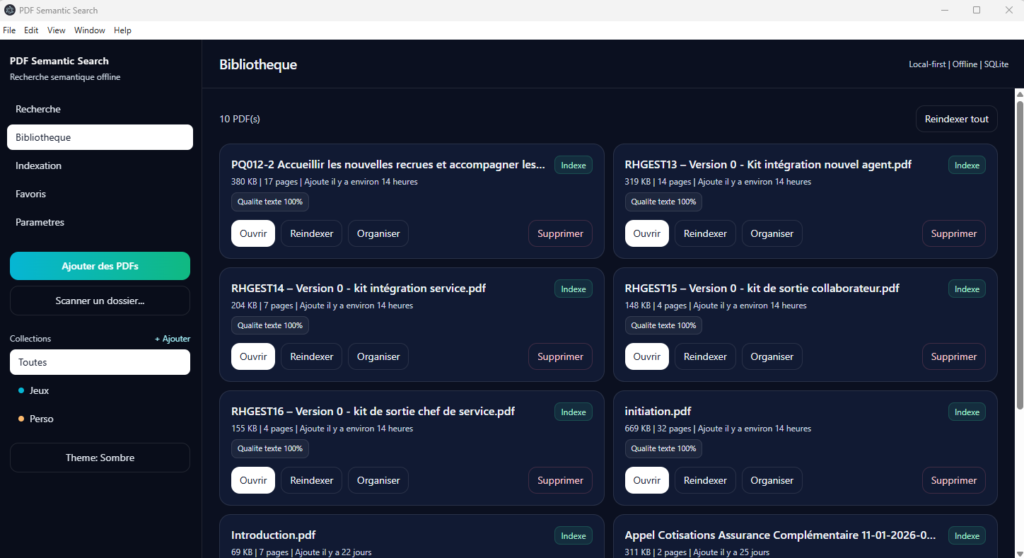
La vue Bibliothèque sert de point d’entrée pour gérer l’ensemble des documents importés dans l’application. Elle affiche les PDF disponibles, leur statut d’indexation, leur taille, leur nombre de pages, ainsi que certaines informations utiles comme la qualité du texte extrait ou l’usage de l’OCR.
Fonctionnalités principales :
- affichage de tous les documents importés ;
- ouverture directe d’un PDF ;
- lancement d’une réindexation ;
- organisation par collections et tags ;
- suppression d’un document de la bibliothèque.
Cette vue joue un rôle central, car elle permet de contrôler l’état réel du corpus documentaire avant même d’effectuer une recherche.
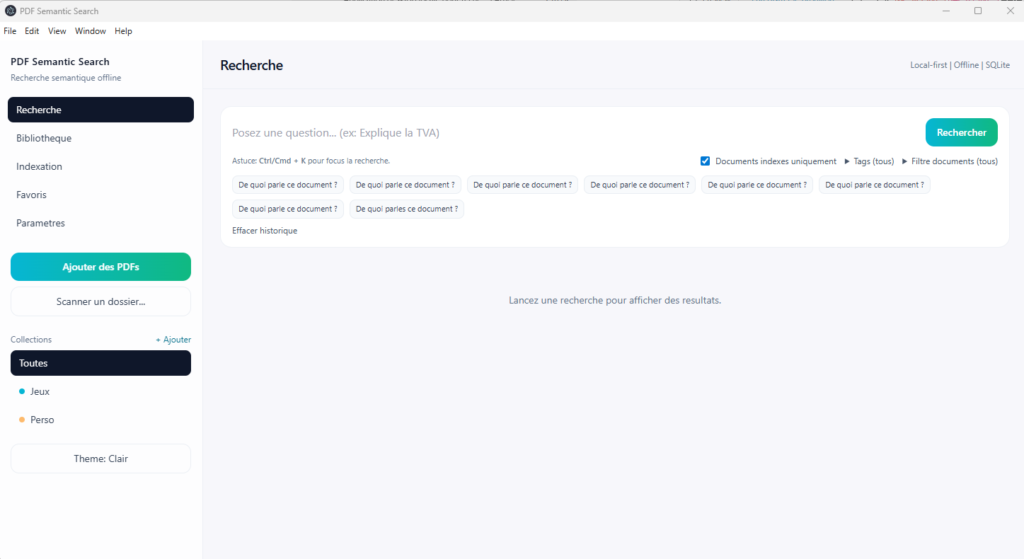
2. La recherche
La vue Recherche est le cœur fonctionnel de l’application. C’est ici que l’utilisateur pose une question, lance une requête documentaire ou recherche un passage précis dans sa bibliothèque.
Fonctionnalités principales :
- recherche hybride par mots-clés et similarité sémantique ;
- filtrage par documents, tags ou collection ;
- affichage de résultats classés avec extraits ;
- réponse extractive rapide avec citations ;
- génération d’une réponse assistée localement.
Cette interface transforme une simple bibliothèque PDF en véritable moteur de recherche documentaire local.
3. Le viewer PDF
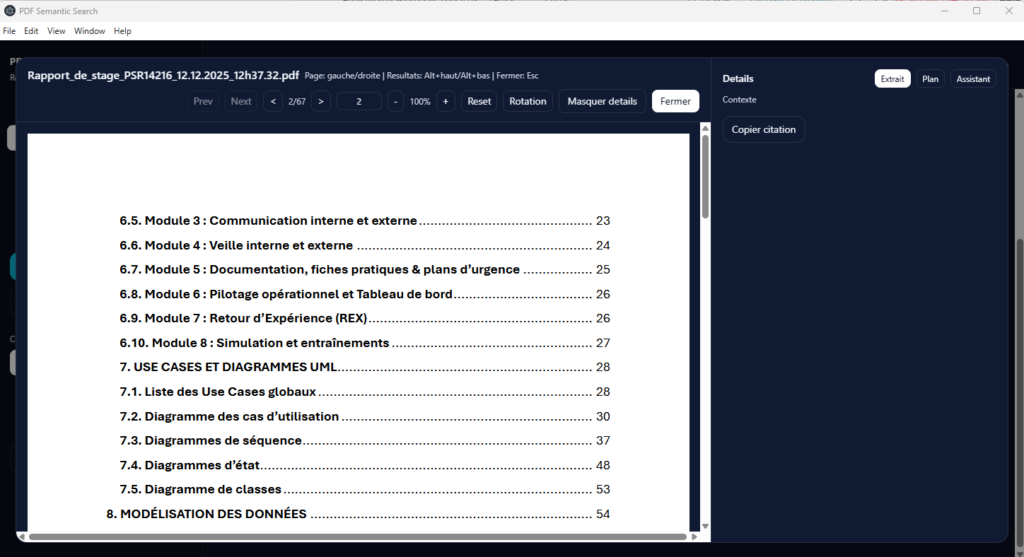
Le viewer PDF permet de consulter les documents directement dans l’application, sans dépendre d’un lecteur externe. Il relie les résultats de recherche à la lecture réelle du fichier, ce qui améliore fortement l’expérience utilisateur.
Fonctionnalités principales :
- ouverture du PDF à la bonne page ;
- zoom, rotation et navigation ;
- surlignage des termes recherchés ;
- affichage du plan du document ;
- consultation du contexte avant et après le passage trouvé.
C’est une interface essentielle, car elle fait le lien entre le moteur de recherche et l’exploitation concrète du document.
4. Le suivi d’indexation
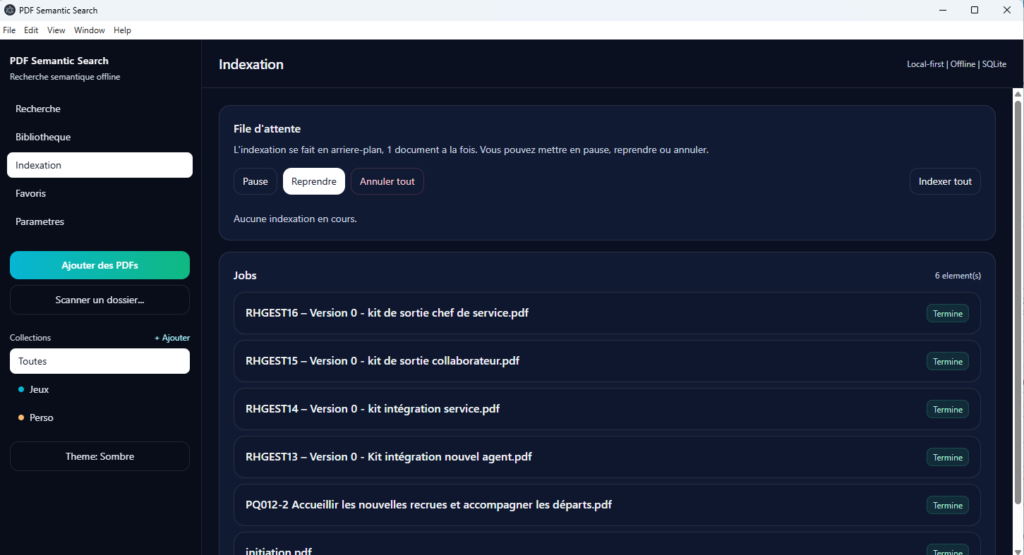
La vue Indexation permet de suivre le traitement des documents en arrière-plan. Elle donne de la visibilité sur une partie souvent cachée dans ce type d’outil, à savoir la préparation technique des données.
Fonctionnalités principales :
- visualisation des tâches d’indexation ;
- suivi de progression ;
- état des documents en file, en cours ou terminés ;
- gestion des erreurs ;
- pause, reprise ou annulation selon les besoins.
Cette vue apporte une vraie dimension professionnelle au projet, car elle rend l’indexation observable et pilotable.
5. Les paramètres
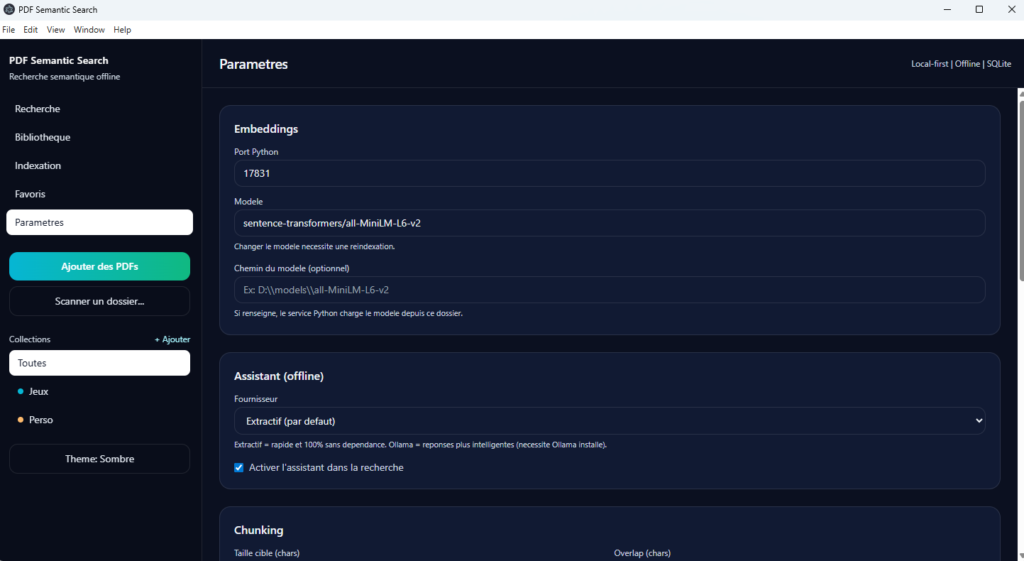
La vue Paramètres permet d’ajuster le comportement de l’application en fonction du contexte d’usage. Elle regroupe les options techniques et fonctionnelles importantes sans alourdir les autres écrans.
Fonctionnalités principales :
- configuration du service d’embeddings ;
- activation et réglage de l’OCR ;
- ajustement du chunking ;
- réglage des pondérations de recherche ;
- configuration de l’assistant local et d’Ollama.
L’application présente d’avantage de vues non illustré ici, je vous laisse les découvrir.
Résumé
Pour conclure, le projet combine une interface desktop claire, une architecture technique assez propre et améliorable, une base SQLite stable de quoi partir sur une bonne base, une recherche hybride pertinente et une couche IA locale capable d’améliorer l’accès à l’information sans dépendre d’un service cloud ou api externe.
Au-delà de l’aspect technique, cette application montre aussi comment construire un vrai produit utile : une interface lisible, des composants bien séparés, une logique métier structurée, une expérience utilisateur orientée efficacité et une base saine pour faire évoluer le projet dans le temps.